
'ROOMS'
RETI NEURALI CHE EVOLVONO PER ‘IMMAGINARE’
In questa simulazione estendiamo il modello della tripletta sensori-motoria per mostrare che questo modello, fornito di pochi elementi e collegamenti aggiuntivi, può acquisire evolutivamente la capacità di produrre un comportamento intenzionale di tipo predittivo se immerso in un ambiente che premi un tale comportamento.
Un’azione volontaria è un'azione della quale prevediamo gli effetti (Parisi, 2006). La capacità di prevedere è basata su memorie di esperienze passate. Ipotizzando che queste memorie siano contenute nelle aree associative e possano essere richiamate da altri settori (in particolare dalle aree prefrontali), abbiamo deciso di verificare se la selezione evolutiva fosse in grado di produrre una rete neurale capace di utilizzare la memoria per prevedere i risultati di un’azione e sfruttare queste previsioni per attuare comportamenti vantaggiosi. Anche se molto semplificata, questa simulazione rappresenta un modello innovativo per lo studio del comportamento intenzionale predittivo.
Metodo
Sinteticamente, una popolazione di 100 reti neurali ‘agenti’ viene fatta agire in un ambiente in cui per produrre comportamenti utili è vantaggioso ricordare le esperienze passate e prevedere i risultati delle azioni future. Ogni rete neurale è costituita da due componenti: una memoria associativa, che conosce (ricorda) l'ambiente, ma non può agire; ed una rete ‘direttiva’, che può evocare ricordi dalla memoria ed agire, sfruttando quei ricordi per ‘scegliere’ le azioni adatte. La memoria è precostituita, perfetta, uguale per tutti gli agenti e invariabile nel tempo. Le reti direttive sono inizialmente casuali, diverse fra tutti gli agenti, e sono fatte evolvere con algoritmo genetico che modifica il numero e le caratteristiche delle loro unità e connessioni, sia ‘interne’ che con la memoria, verso la massimizzazione della fitness.
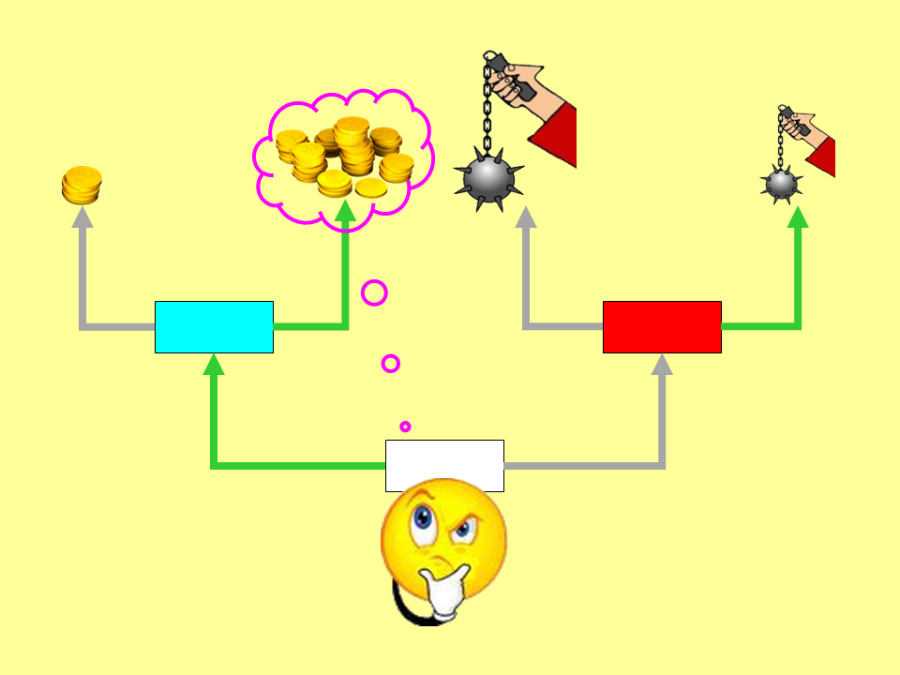
L'ambiente è composto da 24 semplici labirinti a triplo T, ciascuno con 4 uscite che danno agli agenti 4 diversi risultati di fitness: 2 positivi (‘premi’) e 2 negativi (‘punizioni’). Ogni labirinto è composto da tre stanze, ognuna con due porte di uscita. In ogni stanza solo tre azioni sono possibili per gli agenti: prendere la porta a sinistra, a destra, rimanere fermi. Non è possibile riprendere la porta da cui si è entrati ossia tornare indietro. Nella prima stanza, la 'stanza introduttiva', una porta conduce alla 'stanza dei premi', l'altra porta alla 'stanza delle punizioni'. Nella stanza dei premi una porta fa ottenere un grande premio, l'altra un piccolo premio. Nella stanza delle punizioni una porta dà una grande punizione, l'altra una piccola punizione. Ognuna delle tre stanze ha un codice sensoriale diverso (per lo sperimentatore un colore ‘rosso’ ‘bianco’ o ‘blu’). Ciascuno dei 24 labirinti è caratterizzato da una combinazione unica di colori delle stanze e di risultati delle porte. I 24 labirinti coprono tutte le possibili permutazioni di colori delle stanze ed effetti delle porte, escluse le combinazioni in cui un premio ed una punizione sarebbero accessibili dalla stessa stanza.
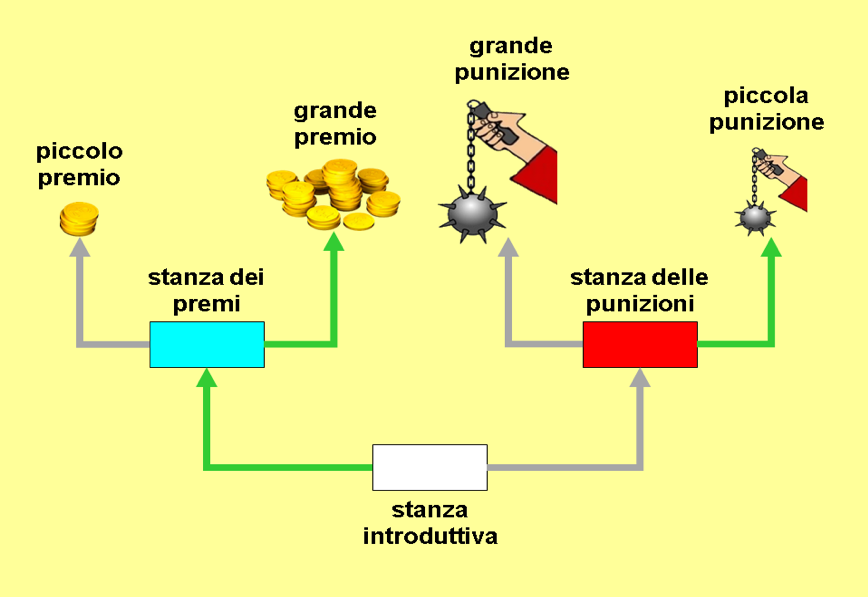
Fig. 81. Uno dei 24 labirinti della simulazione ROOMS. Nella camera blu l’uscita a sinistra determina piccolo aumento della fitness dell’agente (‘piccolo premio’); quella a destra grande aumento (‘grande premio’); nella camera rossa l’uscita a sinistra determina grande diminuzione della fitness (‘grande punizione’); quella a destra piccola diminuzione (‘piccola punizione’). In verde le uscite-azioni migliori (‘adatte’). I 24 labirinti differiscono per i colori delle stanze e le posizioni dei premi e delle punizioni, coprendo tutte le permutazioni possibili escluse quelle in cui un premio ed una punizione sarebbero accessibili dalla stessa stanza.
Ogni agente può percepire il ‘colore’ della stanza in cui si trova, ma non sa se quella sia la stanza introduttiva o quella dei premi o quella delle punizioni, fino a quando la sua memoria non rievoca il ricordo del risultato di una porta di quella stanza. La rete direttiva può anche indurre la memoria a rievocare il ricordo di una stanza diversa da quella in cui l’agente si trova, capacità che vedremo essere molto importante.
Agenti
Il sistema agente (Fig. 82) è costituito da un gruppo di unità di input (sensorialità), un gruppo di unità di output (azione), e, come già anticipato, due reti neurali frapposte fra l’input e l’output: una memoria associativa a tripletta che funziona da memoria fenotipica del labirinto nel quale di volta in volta l’agente è immesso, ed una rete neurale direttiva che riceve i ricordi della memoria, genera le azioni, e può anche indurre la memoria a rievocare ricordi relativi ad una stanza diversa da quella in cui l’agente si trova effettivamente.
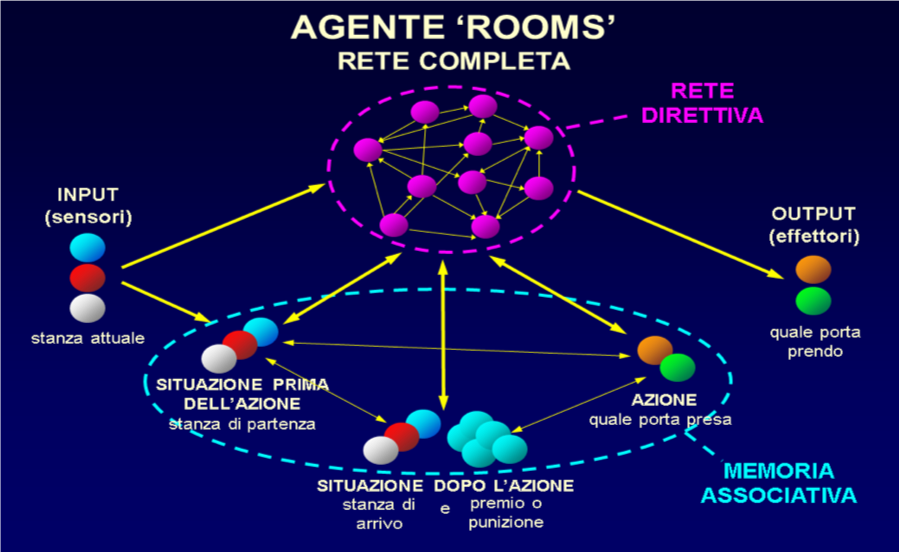
Fig. 82. Rete-agente del modello ROOMS
Rispetto al modello a tripletta ‘classico’ descritto nel cap. 27 ed utilizzato nei modelli ‘ARM’ e ‘POSTURA’ qui le unità di input e di output sono duplicate in modo che quelle di memoria siano attivabili dalla rete direttiva senza interferire con l’input e l’output effettivi-reali. Con questa architettura la rete a tripletta può generare triplette ‘virtuali’ come descritto nel cap. 27 ‘Learning-by-doing’, sezione ‘Generalizzazioni del modello – Triplette virtuali e previsione’. La rievocazione in memoria del ricordo di una stanza diversa da quella in cui l’agente si trova (attivabile solo ad opera della rete direttiva) costituisce di fatto un’immaginazione, ed in questi agenti la distinzione fra immaginazione e realtà menzionata nei capitoli 6 e 26, sezione ‘Memorie associative artificiali’, è insomma ottenuta duplicando le unità coinvolte: quelle direttamente collegate con l’esterno rappresentano la realtà, su quelle della rete a tripletta si formano le immaginazioni.
Ogni agente è testato ‘in solitario’, indipendentemente dagli altri agenti, in tutti i 24 labirinti, tre volte per ogni labirinto: una volta facendolo partire direttamente nella stanza dei premi, una volta nella stanza delle punizioni, ed una volta nella stanza introduttiva. Prima di essere inserito in ciascun labirinto l’agente viene dotato, nella sua rete a tripletta, di una memoria fenotipica di quel labirinto come se l’avesse già interamente esplorato. Tale memoria è preconfezionata, identica per tutti gli agenti e diversa per ciascun labirinto. Se in una stanza l’agente non agisce entro un tempo massimo il test viene concluso con una punizione. La fitness complessiva finale è data dalla somma algebrica dei premi e delle punizioni che l’agente ha ottenuto nei 24 labirinti.
Sensori
Il gruppo di input è costituito da tre unità neurali binarie che codificano il colore (blu, rosso o bianco) della stanza in cui l'agente si trova, ciascuna unità che codifica un colore possibile come stato ‘1’. Queste sono semplici unità lineari, che attraverso connessioni di peso unitario passano inalterati i loro valori di attivazione alle unità di memoria-tripletta che codificano la situazione (stanza) prima dell'azione, ed alle unità della rete direttiva a cui sono collegate. La rete direttiva può comunque sovrascrivere sulle unità di memoria i valori provenienti dalle unità di input con valori ‘immaginari’ da essa generati.
Effettori
Il gruppo di output è costituito da due unità neurali che codificano l'azione che l'agente esegue: l'attivazione della prima unità fa prendere all'agente la porta a sinistra, la seconda la porta a destra, e l'attivazione di entrambe o di nessuna lo fa rimanere fermo. Le unità di output ricevono connessioni (e quindi comandi) solo dalla rete direttiva. La rete a tripletta ha così memoria degli effetti delle diverse azioni nelle diverse stanze, ma non può agire; la rete direttiva può agire, ma per farlo nel modo migliore deve prima interrogare la memoria per conoscere (ricordare) gli effetti delle diverse azioni.
Rete di memoria associativa a tripletta
La struttura della rete a tripletta è simile al modello descritto nel cap. 27 ‘Learning-by-doing’ ed utilizzato nei modelli ‘ARM’ (cap. 32) e ‘POSTURA’ (cap. 33), ma qui tutte le unità hanno connessioni bidirezionali fra tutti e tre i gruppi di unità, in modo che la rete funzioni come memoria associativa e rievochi triplette (virtuali) come descritto nel cap. 27 in ‘Generalizzazioni del modello – Triplette virtuali e previsione’. Sono inoltre unità binarie, con valore di attivazione soltanto 0 o 1.
I tre gruppi della tripletta sono costituiti rispettivamente da tre, otto, e due unità: tre per il ricordo della situazione prima dell'azione (la stanza di partenza), otto per il ricordo della situazione dopo l'azione (la stanza di arrivo ed il premio o la punizione ottenuti), e due per il ricordo dell'azione effettuata. Le stanze e l'azione sono codificate come nell'input e nell'output: tre unità per il colore della stanza e due unità per il prendere la porta di sinistra o di destra o restare fermi. I premi e le punizioni sono codificati in cinque unità indicanti grande premio, piccolo premio, nulla, piccola penalità e grande penalità. Le tre unità codificanti la stanza di partenza ricevono informazioni dalle unità di input sul colore della stanza in cui l'agente si trova, ma le loro attivazioni possono differire da quelle delle unità di input in quanto influenzate anche dalle altre unità di memoria e dalle unità della rete direttiva. Le due unità codificanti l'azione inviano attivazioni anche alle due unità di output, ma l'azione da esse codificata può differire dall'azione effettivamente codificata nelle unità di output (ed attuata dall'individuo), che è influenzata in modo dominante anche dalla rete direttiva.
Rete direttiva
La rete direttiva è una rete neurale non stratificata la cui costituzione è determinata dai processi evolutivi: numero di unità, numero e pesi delle connessioni con le unità di ingresso, con le unità di memoria e con le unità di uscita. Essa può richiedere alla memoria ‘ricordi’ sul labirinto inviandole rappresentazioni sensoriali parziali non corrispondenti alla sensorialità attuale. Ad es., innescare la memoria con il ‘colore’ di una stanza e la ‘scelta’ di una porta, fa sì che la memoria completi la combinazione aggiungendo l’effetto (colore della stanza destinazione o valore del premio/punizione) di prendere quella porta.
Apprendimento
Le reti direttive degli agenti sono sottoposte ad apprendimento genetico tramite algoritmo genetico come in ‘GAZE’: alla fine di ogni generazione, dopo che tutti gli agenti sono stati testati in tutti i labirinti, le loro prestazioni ‘in solitario’ sono messe a confronto, e gli agenti sono riprodotti per la generazione successiva, dando ai migliori un numero di discendenti maggiore rispetto agli altri e mutando ed incrociando a caso i discendenti. A parità di fitness totale sono favoriti nella riproduzione gli agenti che hanno agito più rapidamente.
Esperimenti
Abbiamo simulato una popolazione costituita da un numero fisso e costante di 100 agenti. Come criteri di fine simulazione abbiamo assunto il 95% di azioni corrette (nella stanza dei premi prendere la porta del grande premio; nella stanza delle punizioni prendere la porta della piccola punizione; nella stanza introduttiva prendere la porta che conduce alla stanza dei premi) in tutte le stanze di tutti i labirinti, o 1000 generazioni senza miglioramento maggiore dell’1%. All’inizio della simulazione la rete direttiva di ogni agente è stata inizializzata con un numero casuale di unità tra 2 e 48 e con connessioni di peso casuale da -1 a +1. In ogni generazione ciascun agente è stato testato singolarmente nei 24 labirinti, tre volte per ogni labirinto (v. ‘Agenti’). Alla fine di ogni generazione, dopo che tutti gli agenti hanno eseguito tutti i test, gli agenti sono stati riprodotti per la generazione successiva, sempre in numero totale di 100, in base al loro punteggio finale di fitness, con gli agenti migliori riprodotti in maggiore quantità degli altri e mutando ed incrociando a caso i discendenti.
Abbiamo attuato varie simulazioni con diversi parametri dei valori iniziali casuali e dei premi e punizioni, finché una popolazione non ha soddisfatto il criterio finale del 95% di azioni corrette. A questo punto abbiamo isolato l’agente migliore e lo abbiamo nuovamente testato in tutti i labirinti, analizzando le interazioni tra la sua rete direttiva e la memoria per valutare la strategia di 'ragionamento' della rete direttiva (la sequenza di rievocazioni da essa indotte nella memoria): una sorta di ‘lettura della mente’ (Fig. 83).
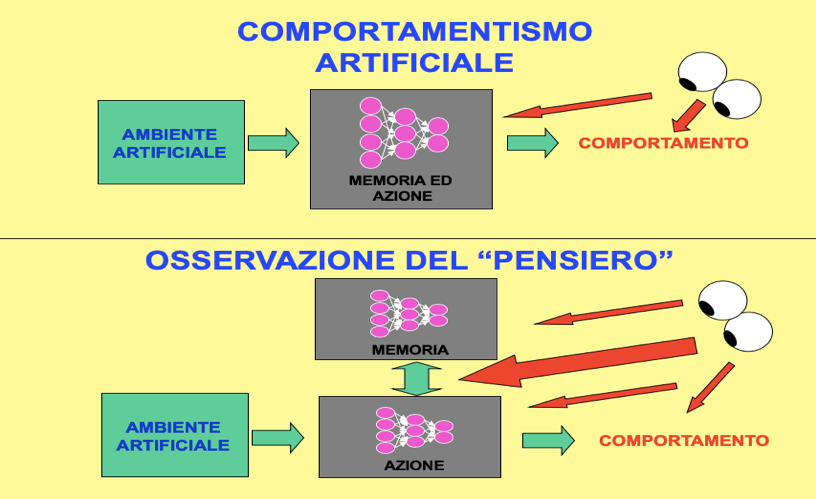
Fig. 83. Il modello ROOMS consente di visualizzare lo scambio d’informazioni tra rete direttiva e la memoria associativa che contiene le informazioni del labirinto nel quale il modello è immesso.
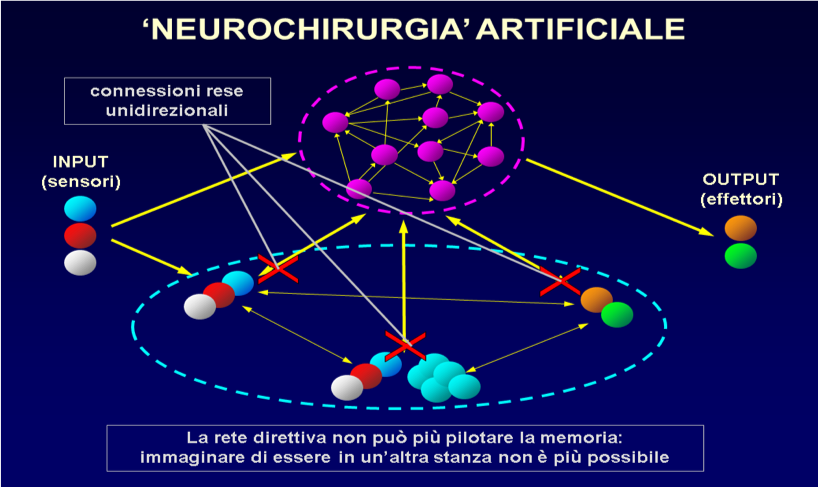
Fig. 84. ‘Lobectomia artificiale’. Le ‘X’ rosse indicano le connessioni interrotte. La rete a tripletta è innescata solo dall’input sensoriale, per cui può rievocare solo ricordi riguardanti la stanza in cui l’agente effettivamente si trova. L’immaginazione è abolita.
Inoltre, per verificare la nostra assunzione che il successo della popolazione si basasse sull’interazione tra la rete direttiva e la memoria, abbiamo condotto una seconda simulazione con una popolazione ‘di controllo’ identica alla prima tranne per il fatto di non avere connessioni dalla rete direttiva alla memoria (Fig. 84): una sorta di ‘lobectomia’.
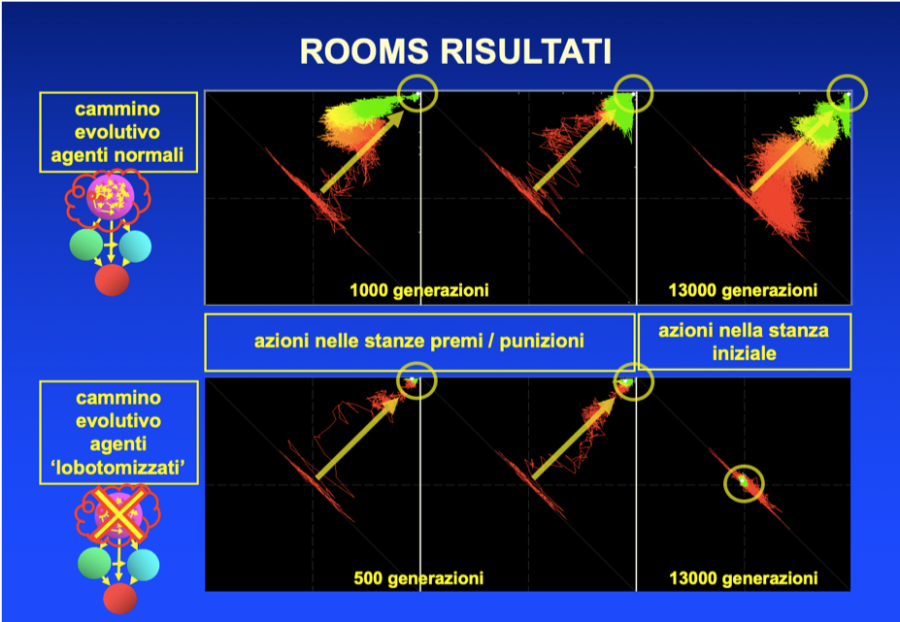
Fig. 85. Percorso evolutivo degli agenti ROOMS. Riquadri superiori: popolazione normale; riquadri inferiori: popolazione priva di connessioni dalla rete direttiva alla memoria. In ogni riquadro: asse orizzontale: percentuale di azioni corrette per la porta a destra (tutti gli agenti in tutti i labirinti); asse verticale: percentuale di azioni corrette per la porta a sinistra. In ogni riquadro il punto centrale corrisponde quindi al 50% di azioni corrette per entrambe le porte (azioni completamente casuali); l’angolo in alto a destra al 100% di azioni corrette per entrambe le porte (obiettivo ideale dell’evoluzione). Riquadri a sinistra: azioni nelle stanze dei premi (tutti i labirinti); riquadri centrali: azioni nelle stanze delle punizioni; riquadri a destra: azioni nelle stanze introduttive. Tratti colorati: risposte medie delle varie generazioni. In verde le generazioni più recenti, in rosso le più antiche.
La popolazione non ‘lobectomizzata’ ha raggiunto in circa 1000 generazioni quasi il 100% di azioni corrette nelle stanze dei premi e delle punizioni, ed in 13000 generazioni il 95% di azioni corrette nella stanza introduttiva. A questo punto dell’evoluzione la rete direttiva risultava di 30 unità in tutti gli agenti. Il percorso evolutivo della popolazione è rappresentato nei tre riquadri superiori di Fig. 85, in forma di traccia colorata dal rosso al verde (in rosso le generazioni più antiche, in verde le più recenti). Ogni tratto della traccia rappresenta la proporzione fra azioni 'giuste' e 'sbagliate' attuate dagli agenti in una generazione, con le azioni riguardanti la porta di sinistra riportate sull'asse verticale e quelle riguardanti la porta di destra sull'asse orizzontale, così che ogni azione giusta porta la traccia verso destra o verso l'alto, ogni azione sbagliata verso sinistra o verso il basso. Il punto centrale rappresenta il 50% di azioni giuste e 50% di azioni sbagliate, corrispondente ad azioni sostanzialmente casuali.
La Fig. 86 (animata) mostra la ‘lettura della mente’ dell’individuo migliore dell’ultima generazione (ad evoluzione avvenuta, dopo 13000 generazioni le reti erano comunque tutte ormai molto simili ed efficienti, con una ‘strategia di ragionamento’ standardizzata ed uniforme). In basso la sequenza d’immaginazioni-rievocazioni richieste dalla rete direttiva alla memoria nella strategia scovata dall’evoluzione per decidere le azioni corrette. Una descrizione più esaustiva si trova nel nostro precedente libro.
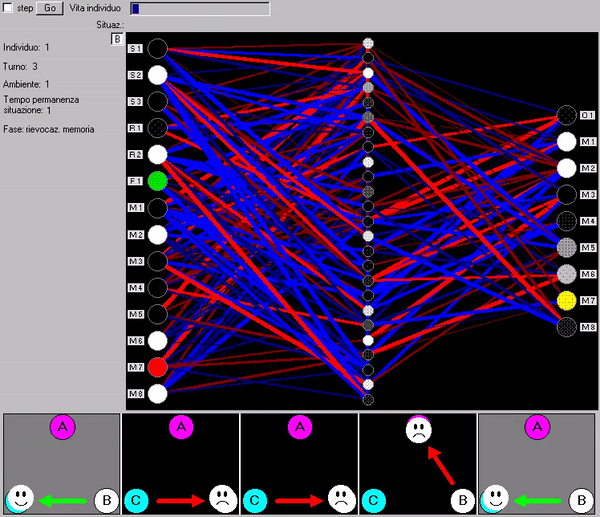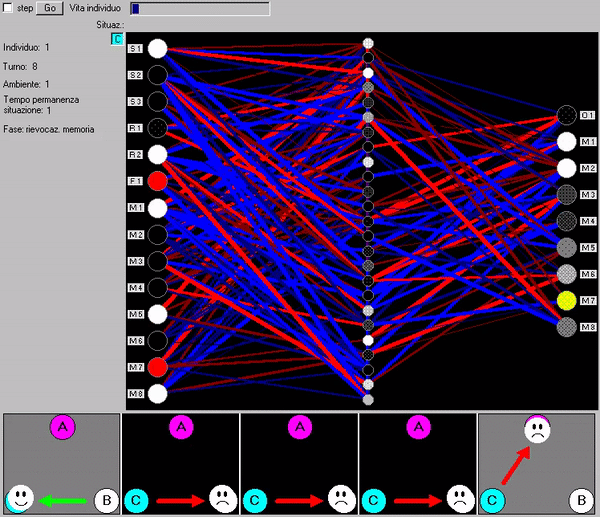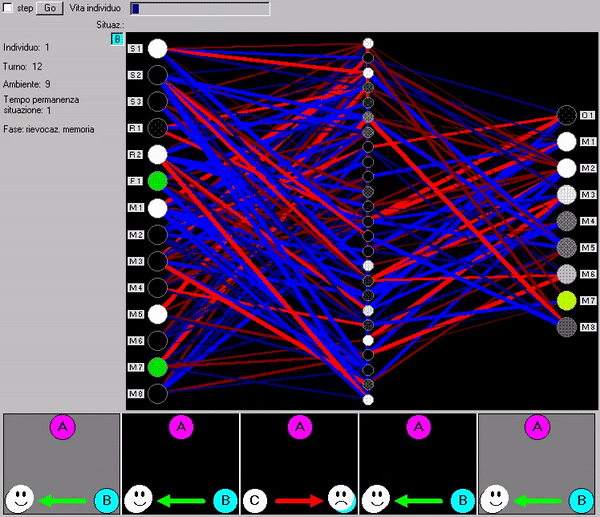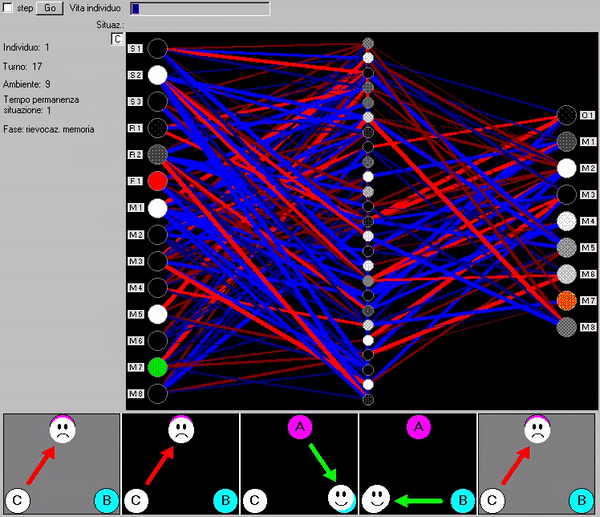
Fig. 86 (animata). Scambio d’informazioni tra la rete direttiva e la rete associativa (memoria)
Di seguito riportiamo la ‘traduzione’ in linguaggio corrente della strategia rilevata da questa analisi. La rete direttiva pone alla memoria da una a tre domande in successione, sempre la medesima sequenza.
La prima domanda è sempre: “Cosa succede se nella stanza in cui mi trovo prendo la porta di sinistra?”
Primo caso: l'agente è in una stanza dei premi o delle punizioni
Se l'agente si trova già in una stanza dei premi o delle punizioni la memoria associativa restituisce una risposta precisa di premio o punizione e della sua entità, ad es. “prenderai la grande punizione”, sulla quale la rete direttiva è in grado di produrre l'azione adatta (nel caso dell'esempio prendere la porta opposta, che fa conseguire la piccola punizione) (Fig. 87).
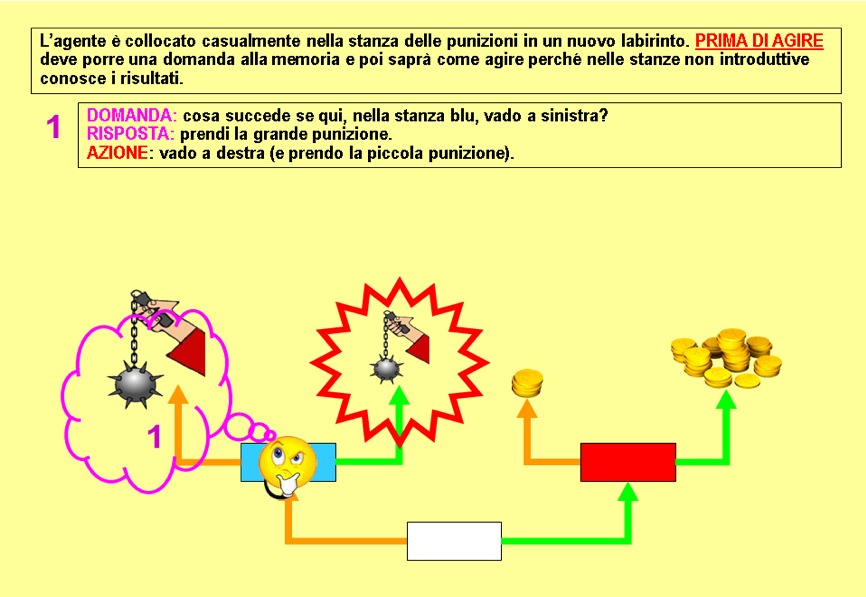
Fig. 87. Processi immaginativi della rete ROOMS. 1° caso. L'agente ricorda che a sinistra prenderebbe la grande punizione. Quindi va a destra.
Se invece l'agente si trova nella stanza introduttiva, la memoria associativa risponde alla domanda indicando come effetto dell'azione una stanza di diverso colore da quella attuale e rivelando così alla rete direttiva di trovarsi nella stanza introduttiva.
Allora la rete direttiva ferma l'agente, ed al secondo turno fa alla memoria associativa una seconda domanda: “che cosa accade se nella stanza dopo la porta a destra (l'altra porta rispetto alla prima domanda) prendo la porta di sinistra?“ È questo il grande contributo della rete direttiva, la capacità d'immaginare una situazione diversa dalla sensorialità attuale, ed attivare con questa la memoria associativa, per ottenere un ricordo-previsione relativo ad un'altra stanza. E qui si danno altri due casi.
Secondo caso: l'agente è nella stanza introduttiva e a destra c’è la stanza dei premi
Se la risposta dalla memoria associativa alla seconda domanda indica un premio, grande o piccolo, la rete direttiva ora sa che la stanza a destra è quella dei premi, e sa anche l’entità del premio di sinistra. A questo punto ha tutte le informazioni necessarie per prendere il grande premio (dalla stanza introduttiva prendere la porta a destra per arrivare alla stanza dei premi, poi prendere la porta identificata dalla seconda risposta, per il grande premio) ed attiva l'agente in tale sequenza (Fig. 88).
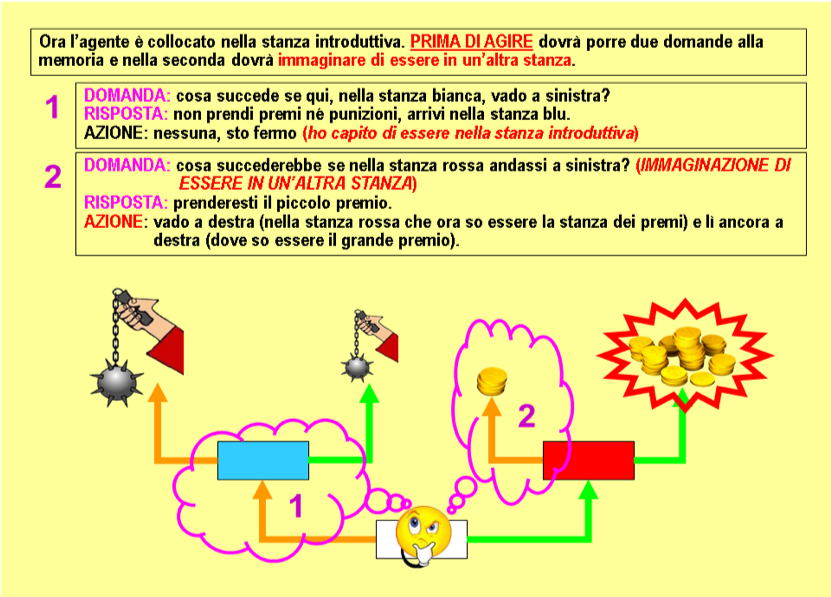
Fig. 88. Processi immaginativi della rete ROOMS. 2° caso. L'agente ricorda che a sinistra non prenderebbe premio né punizione (prima rievocazione), mentre a destra e poi a sinistra prenderebbe il piccolo premio (seconda rievocazione). Ora sa che la stanza a destra è quella dei premi, e lì il piccolo premio è a sinistra. Quindi va a destra e poi ancora a destra.
Terzo caso: l'agente è nella stanza introduttiva e a destra c’è la stanza delle punizioni
Se in caso contrario la risposta alla seconda domanda indica una punizione, la rete esecutiva ordina all'agente di prendere la porta a sinistra dalla stanza introduttiva, andando così nella stanza dei premi, e lì, ripetendo la domanda del primo caso, saprà quale porta conduce al grande premio (Fig. 89).
Con questa strategia gli agenti, quando sono nelle stanze premi o punizioni, possono risolvere qualsiasi labirinto in un solo turno; in due turni quando partono invece dalla stanza introduttiva e la stanza dei premi è a destra; in tre turni quando partono dalla stanza introduttiva e la stanza dei premi è a sinistra. La simulazione ha quindi sviluppato evolutivamente una strategia che consente ad ogni agente, con una sequenza standard di domande alla propria memoria, di ottenere il risultato ottimale in tutti i labirinti, in qualunque stanza venga casualmente collocato alla partenza. È comparsa la capacità d'immaginare il risultato di una scelta comportamentale in una stanza futura e l’immaginazione è il presupposto per il pensiero.
Per quanto concerne invece i risultati della popolazione di controllo ‘lobotomizzata’, questa nelle stanze dei premi e delle punizioni ha raggiunto quasi il 100% di azioni giuste dopo appena 500 generazioni, ma nella stanza iniziale anche dopo 13000 generazioni non si è mai spostata dal 50% corrispondente ad azioni casuali (Fig. 85, riquadri inferiori). L’evoluzione in questo caso ha prodotto una rete direttiva di sole 3 unità (contro le 30 della popolazione ‘normale’).

Fig. 89. Processi immaginativi della rete ROOMS. 3° caso. L'agente ricorda che a sinistra non prenderebbe premio né punizione (prima rievocazione), mentre se andasse a destra e poi a sinistra prenderebbe la piccola punizione (seconda rievocazione). Ora sa che la stanza a destra è quella delle punizioni, quindi va a sinistra. Lì ricorda che a sinistra prenderebbe il piccolo premio (terza rievocazione), quindi va a destra.
Discussione e conclusioni
Nella progettazione di questa simulazione abbiamo scelto di preconfezionare i ricordi della memoria associativa, piuttosto che farla apprendere veri ricordi del singolo agente, perché avevamo bisogno di privare le reti della loro capacità d’ apprendimento, che avrebbe potuto produrre ‘riflessi’ a scapito del ‘pensiero’. Nel nostro esperimento desideravamo che la popolazione sviluppasse pensieri, non riflessi. Questo è molto diverso dai reali sistemi nervosi, in cui un’esperienza ripetuta porta ad un comportamento automatico: abbiamo già detto che in caso di esperienze ripetitive il sistema nervoso tende a produrre riflessi, come nell'esempio della guida di veicoli. Abbiamo risolto questo problema consentendo apprendimento soltanto genetico nelle reti direttive, e nessun apprendimento nelle memorie associative.
L'apprendimento genetico è in grado di cogliere solo le caratteristiche ambientali costanti, ma l'ambiente progettato non conteneva caratteristiche costanti, dal momento che i 24 labirinti erano tutti diversi nelle loro caratteristiche. Ci attendevamo quindi che l’evoluzione scovasse l’unica costante possibile, una strategia di comportamento valida per tutti i labirinti, cosa che i risultati hanno confermato. La nostra tesi che un sistema di questo tipo utilizzi l’interazione di una componente direttiva con una componente di memoria, in cui la componente direttiva induce opportune rievocazioni dalla componente di memoria e le utilizza per decidere il comportamento, appare confermato dalla ‘lettura della mente’ del migliore agente, e dal fallimento della popolazione di controllo in cui tale interazione era impedita.
Il conseguimento della capacità di attuare azioni corrette nelle stanze dei premi e delle punizioniagire anche da parte della popolazione di controllo è particolarmente interessante. Sebbene nelle popolazioni simulate avessimo reso impossibile lo sviluppo di riflessi propriamente detti, ossia di azioni comandate direttamente dalla memoria associativa senza l’intervento della rete direttiva, nella popolazione di controllo era abolita la possibilità per la rete direttiva di comandare la memoria, ma non la possibilità per la memoria di dare alla rete direttiva informazioni sulla situazione reale-attuale. Anche se non riceveva connessioni dalla rete direttiva la memoria riceveva ancora, direttamente dalle unità di input alle sue unità ‘situazione prima dell’azione’ (Figg. 82, 84), informazione circa la stanza reale-attuale in cui l’agente si trovava (il colore della stanza), e poteva quindi rievocare ricordi relativi a quella stanza (mentre non poteva rievocare ricordi relativi ad un’altra stanza, ossia immaginare). Poiché le connessioni dalla memoria alla rete direttiva, diversamente da quelle in verso opposto, erano risparmiate, la rete direttiva poteva ‘leggere’ quei ricordi, e nelle stanze del premio o della punizione tali ricordi sono sufficienti per attuare l’azione corretta. In quelle stanze la rete direttiva non è necessaria, se non per invertire l'azione nei casi in cui la memoria rievoca un'azione con risultato sfavorevole, ad es. per prendere la porta di destra quando la memoria informa che quella di sinistra dà piccolo premio o grande punizione. Invece nella stanza introduttiva la memoria, per poter rievocare un premio o una punizione, deve essere attivata con il colore di un'altra stanza, vale a dire con una sensorialità immaginata, l'immaginazione di essere in un'altra stanza; attivazione che solo la rete direttiva può generare. Questo spiega il successo della popolazione ‘lobectomizzata’ nelle stanze del premio e della punizione, e solo in quelle. A conferma di ciò vi è anche il fatto che in questa popolazione l’evoluzione ha prodotto una rete direttiva di sole 3 unità, evidentemente sufficienti a confermare o invertire l’azione rievocata dalla memoria. Tutto questo conferma che senza l’apporto 'immaginativo' della rete direttiva il sistema è in grado di sviluppare solo un 'pensiero concreto' (ricordi pertinenti solo al contesto, previsioni confinate alla situazione reale attuale), e lo fa anche molto rapidamente; ma non è in grado di formulare previsioni relative a situazioni diverse e immaginarie, che invece fa efficacemente quando è presente una rete direttiva. Questo potrebbe anche costituire un modello per il pensiero concreto o ‘concretismo’ presente in alcune psicopatologie umane, quali le condizioni di oligofrenia o demenza lieve o moderata.
Come abbiamo detto più volte un atto volontario è un'azione intrapresa dopo aver previsto i suoi effetti, il che costituisce un notevole vantaggio nella selezione evolutiva. I risultati di questi esperimenti mostrano inequivocabilmente che anche in un sistema artificiale, sottoposto a meccanismi evolutivi analoghi a quelli naturali ed immerso in un ambiente ove la capacità di ricordare – prevedere – immaginare il risultato del comportamento sia vantaggiosa o necessaria, compaiono strutture neurali artificiali in grado di farlo.